Deep Learning Face Representation by Joint Identification-Verification
Main Contribution
这篇论文使用deep learning学习特征,使用联合贝叶斯模型作为分类器,选取七组特征分别训练分类器,得到的结果使用SVM进行组合,得到的最终模型在LFW(Labeled Face in the Wild)数据集上的人脸验证任务中,达到了99.15%的准确率,目前排名第一。
Basic Concepts and Ideas
Face Identification,人脸识别,将一个输入图像进行分类,类别集合会很大。
Face verification,人脸验证,对两个图像进行判断,确认是不是同一个人的图像。
论文的主要创新点就是利用deep learning学习图像特征,具体的创新点就是通过扩大类间距离和缩小类内距离。
Pipeline
论文提出的人脸识别算法流程如下:
首先,使用SDM算法抽取人脸上的21个标记,然后根据得到的标记对人脸进行对齐。通过变化位置、尺度、颜色通道,得到200个face patch,对每个face patch,使用该patch及其水平反转的图像进行特征学习。所以,一共需要200个深度卷积神经网络。
注:因为LFW是wild数据,不像AR数据集那样是对齐好的数据,所以需要通过SDM寻找landmark来分patch;SDM算法是CVPR2013年提取的。
第二步,学习特征,论文提出一种学习特征的卷积神经网络框架,称之为DeepID2。构建200个DeepID2来学习上一步得到的patch。每个DeepID2都将输入图像表示成一个160维的向量。
第三步,对每张图像而言,经过200个DeepID2学习到的特征数目为200*160,特征数目太大了。所以论文中使用前向后向贪心算法来选取一些有效且互补的DeepID2向量,以节约时间。注意,特征选择在每个DeepID2向量间进行,也就是一个DeepID2输出的向量,要么全被选中,要么全不被选中。选中的向量对应的patch如图。

第四步,选中25个向量后,每张图像的维度是25*160=4000维。仍然太大,因而使用PCA进行降维,降维后大约有180维。
第五步,对于输出后的向量,就可以使用来进行人脸验证任务了。论文构建了一个联合贝叶斯模型来进行分类。联合贝叶斯模型如下:
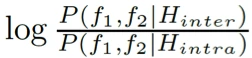
即使用类间距除以类内距的对数值来衡量一个图像对是不是同一个人。在训练集上可以得到一个阈值,当结果值大于阈值时,不是同一个人;当结果值小于阈值时,是同一个人。
DeepID2
DeepID2的创新点在于在学习特征的时候,该网络不仅考虑分类准确率,还考虑类间差距。具体的做法就是在目标函数中添加一项类间差距。该添加的创新就在于类间差距是在两个样本间进行衡量的,因而添加类间差距后,训练过程需要变化。
DeepID2所做的第二点小创新就是将卷积层的倒数第一层和倒数第二层都作为最终层的输入。(因为添加了类间差距,所以最终层不能再成为是softmax层了)
DeepID2学习特征的整体卷积神经网络结构图如下:
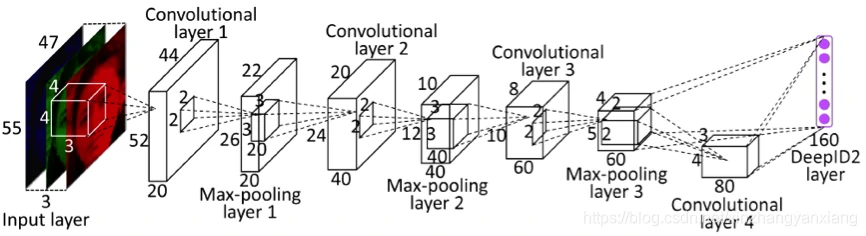
Details of Structure
四层卷积,前三层后面都跟着max-pooling层,第三层卷积的神经单元的参数在2*2的局部区域内共享;第四层卷积则是全连接,参数在神经单元之间不共享。
第三卷积层的输出和第四卷积层的输出以全连接的方式连接到最后一层,最后一层也称为DeepID2层。因为第四层学习到的特征比第三层的更全局一些,所以这样的连接方式被称为是多尺度卷积神经网络。
Goal functions
在本论文中,使用DeepID2进行学习的目的是得到输出向量,并不是为了使识别率最大化。因而论文添加了类间距项。使用卷积层得到输出向量可用函数表示:
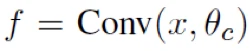
正确分类的函数就是softmax的目标函数,目的是使交叉熵最小化。
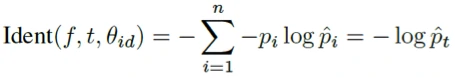
样本间距最大化的目标函数如下。
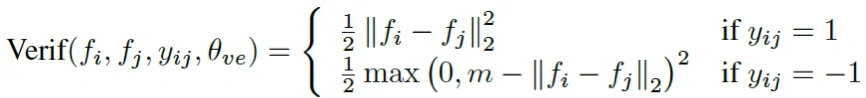
该公式的作用是,当两个样本相同时,则需要最小化它们之间的距离,当两个样本不同时,则需要最小化m与它们的距离值之差,m是一个需要手动调整的参数,提出m的目的在于目标函数需要最小化,而不是最大化。
当样本之间的距离函数时余弦距离时,样本间距最大化的目标函数如下。
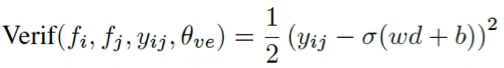
在最终组合目标函数时,将Ident与Verif加权。
Training process
训练过程如下图。

Experiment
Experiment datasets
LFW是最终使用模型的数据集,共13233张脸,分属于5749个人。但此数据集太小,所以需要引入外部数据集CelebFace+,拥有202599张脸,分属于10177个人。
将CelebFace+数据集分为CelebFace+A数据集和CelebFace+B数据集。CelebFace+A有8192个人的数据,随机从CelebFace+中选取,用于训练DeepID2学习特征。CelebFace+B是剩余的1985个人的脸,用来进行特征选取和联合贝叶斯概率模型的学习。
在学习DeepID2的时候,CelebFace+A是训练集,CelebFace+B是验证集来确定学习速率,训练迭代次数,目标函数的融合参数lambda。
在特征选择的时候,CelebFace+B中分出500个人的数据作为验证集。
最后,在整个CelebFace+B中训练联合贝叶斯模型。
在LFW上使用训练好的模型进行实验。
Experiment settings
论文进行了如下几组实验:
- 考察目标函数融合参数lambda的效果,包括最终效果分析、方差分析、PCA降至2维时的数据分析。
- 考察信息量的影响,即通过变换训练集的大小(32指数增长到8192),查看效果。
- 改变用于验证的目标函数即Verif的距离计算方法后的实验效果。考察了一阶范数、余弦距离等。
- 选取了七组不同的特征集合,然后将模型使用svm进行融合,得到最终结果99.15%。
Reference
[1] Sun Y, Chen Y, Wang X, et al. Deep learning face representation by joint identification-verification[C]//Advances in Neural Information Processing Systems. 2014: 1988-1996.
参考资料
版权声明:本文为CSDN博主「张雨石」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/stdcoutzyx/article/details/41497545